|
БАЗИ ДАНИХ. МОВИ ЗАПИТІВ, УПРАВЛІННЯ ТРАНЗАКЦІЯМИ, РОЗПОДІЛЕНА ОБРОБКА ДАНИХ |
|
3. Розподілені бази даних
3.1 Концепція розподілених баз даних
3.1.1 Основні поняття
даних та паралельними системами баз даних
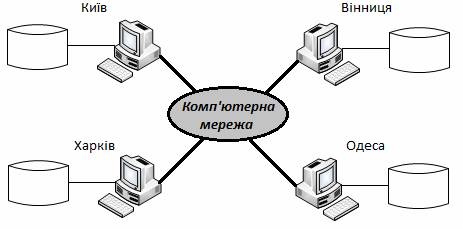
Основною передумовою розробки систем, що використовують бази даних, є прагнення об’єднати всі дані, які обробляються на підприємстві, в єдине ціле та забезпечити контрольований доступ до них. Сучасні потужні підприємства часто мають велику кількість підрозділів, які можуть фізично розташовуватись за сотні та навіть тисячі кілометрів один від одного. Кожний з цих підрозділів має свою локальну базу даних. Якщо ці бази мають різні архітектури та використовують різні протоколи зв’язку, то їх розглядають як інформаційні острови, важкодоступні для інших. В такому випадку виникає необхідність об’єднати розрізнені бази даних в одне логічне ціле, тобто створити розподілену базу даних. Розподілена база даних – це сукупність логічно зв’язаних баз даних або частин однієї бази, які розпаралелені між декількома територіально-розподіленими ПЕОМ і забезпечені відповідними можливостями для управління цими базами або їх частинами. Тобто, розподілена база даних реалізується на різних просторово розосереджених обчислювальних засобах, разом з організаційними, технічними і програмними засобами її створення і ведення. В дійсності розподілена база даних є віртуальною базою даних, компоненти якої фізично зберігаються на декількох різних реальних базах даних на декількох різних вузлах. На рис.3.1 наведено приклад типової топології розподіленої бази даних.
Рисунок 3.1 – Приклад типової топології розподіленої бази даних
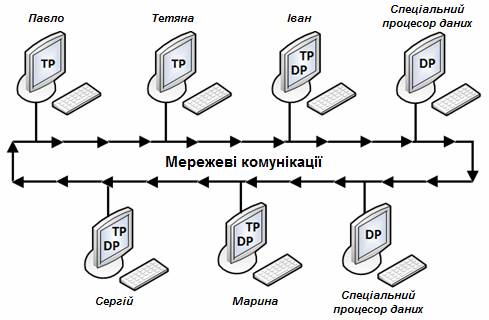
Використовувати розподілені бази даних ефективно і доцільно в предметних областях, які характеризуються: - занадто великими обсягами даних, які зберігаються і обробляються; - фізичною розосередженістю місць збирання, зберігання і використання даних; - наявністю розвинутих засобів обчислювальної техніки і мереж передачі даних; - можливістю обробки більшої частини інформації в місцях, де вона виникає або зберігається; - необхідністю одночасного виконання масової обробки інформації тощо. Розподілена система керування базою даних (СКБД) – це програмний комплекс, призначений для управління розподіленими базами даних і забезпечує прозорий доступ користувачів до розподіленої інформації. Прозорий доступ означає непомітний для користувача, тобто у користувача має складатися враження ніби він працює з єдиною базою даних, яка розміщена на його власному комп’ютері. Розподілена СКБД, порівняно з централізованою СКБД, повинна мати додатковий набір функціональних можливостей: - розширені служби встановлення з'єднань повинні забезпечувати доступ до віддалених вузлів і дозволяти передавати запити і дані між вузлами, які входять у мережу; - розширені засоби ведення каталогу, що дозволяють зберігати відомості про розподіл даних в мережі; - засоби обробки розподілених запитів, включаючи механізми оптимізації запитів і організації віддаленого доступу до даних; - розширені функції управління захистом, що дозволяють забезпечити дотримання правил авторизації та прав доступ до розподілених даних; - розширені функції управління паралельним виконанням, які дозволяють підтримувати цілісність копіювання; - розширені функції відновлення, що враховують ймовірність відмов в роботі окремих вузлів і відмов ліній зв'язку. Всі функції розподіленої СКБД мають виконуватись прозоро для користувача. До складу розподіленої СКБД повинні входити такі компоненти: - комп'ютерні робочі станції (сайти або вузли), що формують мережеву систему; - компоненти мережевого обладнання та програмного забезпечення кожної робочої станції, які дозволяють усім вузлам взаємодіяти один з одним та обмінюватися даними; - комунікаційні пристрої, які переносять дані з однієї робочої станції на іншу; - процесор транзакцій (transaction processor, TP) – програмний компонент, що знаходиться на кожному комп'ютері, де виконується запит даних. Процесор транзакцій отримує і обробляє запити (віддалені та локальні); - процесор даних (data processor, DP) – програмний компонент, розташований на кожному комп'ютері, де зберігаються і обробляються дані, розташовані на даному вузлі. Процесор даних може навіть являти собою централізовану СКБД. На рис.3.2 показано розміщення і взаємодію усіх компонентів розподіленої СКБД.
Рисунок 3.2 – Взаємодія компонентів системи розподіленої БД
Кожний ТР може отримати доступ до даних на будь-якому DP і кожний DP обробляє всі запити локальних даних від будь-якого ТР. Зв'язок між ТР і DP здійснюється відповідно до специфічних правил або протоколів, які визначають, як система розподіленої бази даних: - організовує інтерфейс з мережею для передачі даних і команд між процесорами даних (DP) і процесорами транзакцій (ТР); - синхронізує всі дані, отримані від DP, і передає отримані дані на відповідні ТР; - забезпечує функції загального управління БД в розподіленій системі (безпека, управління паралельним виконанням, створення резервних копій і відновлення). Процесори ТР і DP можуть бути розміщені на одному і тому ж комп’ютері, дозволяючи користувачам отримувати доступ до локальних і віддалених даних, не турбуючись про їх місцезнаходження. Теоретично DP може представляти собою незалежну централізовану СКБД з відповідним інтерфейсом для підтримки віддаленого доступу до інших незалежних СКБД в мережі. Одним із різновидів розподіленої СКБД є мультибазова система – розподілена система управління базами даних, в якій управління кожним вузлом здійснюється автономно. Мультибазові системи дозволяють кінцевим користувачам різних вузлів отримувати доступ і спільно використовувати дані без необхідності фізичної інтеграції існуючих баз даних. Вони забезпечують користувачам можливість управляти базами даних їх власних вузлів без будь-якого централізованого контролю, який обов'язково присутній у звичайних типах розподілених СКБД. Адміністратор локальної бази даних може дозволити доступ до певної частини своєї бази даних за допомогою створення схеми експорту, яка визначає, до яких елементів локальної бази даних зможуть отримувати доступ зовнішні користувачі. Існують так звані необ'єднані (не мають локальних користувачів) і об'єднані мультибазові системи. Об'єднана система являє собою деякий гібрид розподіленої та централізованої систем, оскільки вона виглядає як розподілена система для віддалених користувачів і як централізована система – для локальних. Іншими словами, мультибазова СКБД непомітно для користувача розміщується над існуючими системами баз даних і файловими системами і розглядається користувачами як єдина база даних. Мультибазова СКБД підтримує глобальну схему, на основі якої користувачі можуть формувати запити і модифікувати дані. Мультибазова СКБД працює тільки з глобальною схемою, тоді як локальні СКБД власними силами забезпечують підтримку даних всіх своїх користувачів. Глобальна схема створюється шляхом об'єднання схем локальних баз даних. Програмне забезпечення мультибазової СКБД попередньо транслює глобальні запити і перетворює їх на запити та оператори модифікації даних відповідних локальних СКБД. Потім отримані після виконання локальних запитів результати зливаються в єдиний глобальний результуючий набір, що надається користувачеві. Крім того, мультибазова СКБД здійснює контроль за виконанням фіксації або відкату окремих операцій глобальних транзакцій локальних СКБД, а також забезпечує збереження цілісності даних в кожній з локальних баз даних. Програми мультибазової СКБД управляють різними шлюзами, за допомогою яких вони контролюють роботу локальних СКБД. Одним із прикладів мультибазової системи є система UniSQL компанії Cincom Corporation. Вона дозволяє розробляти програми за допомогою єдиного глобального уявлення і єдиної мови доступу до бази даних для роботи з багатьма різнорідними реляційними і об'єктно-орієнтованими СКБД.
3.1.2 Відмінності між розподіленими системами баз даних, засобами розподіленої обробки даних та паралельними системами баз даних
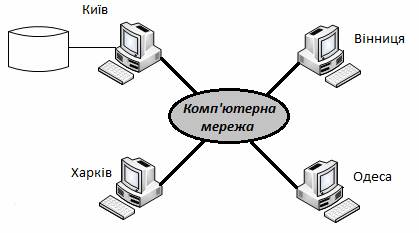
Дуже важливо розуміти відмінність між розподіленими системами баз даних і засобами розподіленої обробки даних. Розподілена обробка даних (distributed processing) використовує централізовану базу даних, доступ до якої може здійснюватись з різних комп’ютерів мережі. Вузол, на якому розміщена база даних, називають сервером бази даних. Ключовим моментом у визначенні розподіленої СКБД є твердження, що система працює з даними, які фізично розподілені в мережі, тобто фрагменти розподіленої бази даних розміщені на різних вузлах. Топологію системи розподіленої обробки даних зображено на рис. 3.3. Як видно з рисунка 3.3, база даних розміщена лише на одному вузлі, в той час як на рис. 3.1 можна побачити, що в розподіленій СКБД кожен вузол може містити свій фрагмент розподіленої бази даних.
Рисунок 3.3 – Топологія середовища розподіленої обробки даних
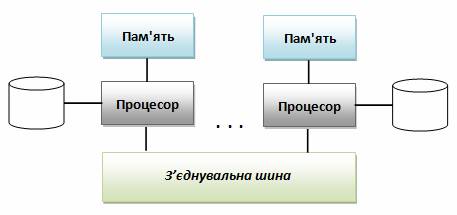
При розподіленій обробці даних логічні процеси бази даних розподіляються серед двох або більше фізично незалежних вузлів, об'єднаних в мережу. Наприклад, розподілена обробка може виконувати введення/виведення даних, вибірку даних і перевірку даних на одному комп'ютері, а на іншому комп'ютері випускати звіт на основі отриманої інформації. Кожен вузол може мати доступ до даних та оновлювати базу даних. Розподілена обробка даних не вимагає розподіленої бази даних, але розподілена база даних обов'язково вимагає розподіленої обробки інформації. Спільною рисою розподіленої обробки даних і розподіленої бази даних є необхідність в локальній мережі, яка зв'язує всі компоненти між собою. Також варто розуміти відмінності, які існують між розподіленими і паралельними СКБД. Паралельна СКБД функціонує з використанням декількох процесорів і жорстких дисків, що дозволяє їй розпаралелити виконання деяких операцій з метою підвищення загальної продуктивності обробки. Застосування паралельних СКБД дозволяє об’єднати декілька малопотужних машин для отримання такого ж рівня продуктивності, що й у випадку однієї більш потужної машини, але при цьому досягається вищий рівень масштабованості та надійності системи в порівнянні з однопроцесорною СКБД. Для надання декільком процесорам спільного доступу до однієї і тієї ж бази даних паралельна СКБД повинна забезпечувати управління сумісним доступом до ресурсів. Залежно від того, які саме ресурси поділяються, розрізняють три види паралельних СКБД: - системи з поділом пам'яті; - системи з поділом дисків; - системи без поділу обчислювальних ресурсів. Паралельна система без поділу обчислювальних ресурсів іноді розглядається як розподілена СКБД, однак в такій системі розподіл даних зумовлений лише прагненням до підвищення продуктивності. Крім того, вузли розподіленої СКБД зазвичай розділені географічно, знаходяться під управлінням різних адміністраторів і з'єднані між собою відносно повільними мережевими з'єднаннями, тоді як вузли паралельної СКБД найчастіше розташовуються на одному і тому ж комп'ютері або в межах одного і того ж виробничого майданчика. Архітектура системи баз даних з паралельною обробкою зображена без поділу обчислювальних ресурсів на рис.3.4. Системи з поділом пам'яті складаються з тісно пов'язаних між собою компонентів, до числа яких входить кілька процесорів, які поділяють загальну системну пам'ять. Ця архітектура, яку ще називають архітектурою з симетричною багатопроцесорною обробкою (SMP), на даний час отримала широке поширення і застосовується для найрізноманітніших обчислювальних платформ, від персональних робочих станцій, що містять кілька паралельно працюючих мікропроцесорів, великих RISC-систем і до найбільших мейнфреймів. Ця архітектура забезпечує швидкий доступ до даних для обмеженого набору процесорів, кількість яких звичайно не перевершує 64. В іншому випадку взаємодія по мережі стає вузьким місцем всієї системи. Системи з поділом дисків створюються з менш тісно пов'язаних між собою компонентів. Вони є оптимальним варіантом для додатків, які успадкували високу централізацію обробки і повинні забезпечувати найвищі показники доступності та продуктивності. Кожен з процесорів має безпосередній доступ до всіх спільно використовуваних дискових пристроїв, але має власну оперативну пам'ять. Як і у випадку архітектури без поділу обчислювальних ресурсів, архітектура з поділом дисків виключає вузькі місця, пов'язані з спільно використовуваною пам'яттю. Однак, на відміну від архітектури без поділу обчислювальних ресурсів, дана архітектура виключає згадані вузькі місця без внесення додаткових витрат, пов'язаних з фізичним розподілом даних по окремим пристроям. Колективні дискові системи іноді називають кластерами.
Рисунок 3.4 – Архітектура системи баз даних з паралельною обробкою без поділу обчислювальних ресурсів
Системи без поділу обчислювальних ресурсів (цю архітектуру інакше називають архітектурою з масовою паралельною обробкою) використовують схему, в якій кожен процесор, який є частиною системи, має свою власну оперативну і дискову пам'ять. База даних розподілена між всіма дисковими пристроями, які підключені до окремих, пов'язаних з цією базою даних обчислювальних підсистем, в результаті чого всі дані прозоро доступні користувачам кожної з цих підсистем. Така архітектура забезпечує більш високий рівень масштабованості, ніж системи з поділом пам’яті, і дозволяє легко підтримувати велику кількість процесорів. Однак оптимальна продуктивність буде досягнута тільки в тому випадку, якщо необхідні дані зберігаються локально. Паралельні технології зазвичай використовуються у випадку виключно великих баз даних, розміри яких можуть досягати декількох терабайт (1012 байт), або в системах, які забезпечують виконання тисяч транзакцій в секунду. Подібні системи потребують доступу до великого обсягу даних і повинні забезпечувати прийнятний час реакції на запит.
3.1.3 Класифікація розподілених баз даних
За способом розміщення розподілені бази даних ділять на зосереджені і розосереджені. Зосереджені (або централізовані) розподілені бази даних фізично розміщені в одному місці. Для обміну інформацією між окремими (локальними) півбазами використовуються канали зв’язку прямого доступу. Обмін даними між взаємозв’язаними півбазами здійснюється без помітних обмежень на обсяги і характер інформації, що передається. Такі бази даних мають ряд переваг: - просту побудову бази даних, - зведення до мінімуму дублювання інформації, - максимальну уніфікацію методів зберігання, коригування і пошуку інформації. Проте зосереджені бази даних в одному місці – вузлі мережі – мають цілий ряд недоліків: при централізації зберігання значно збільшується час на передачу інформації і за рахунок цього зростає час реакції системи; централізована система обмежена обсягами пам’яті ЕОМ тощо. Розосереджені (або децентралізовані) розподілені бази даних фізично розміщені в різних місцях – вузлах обчислювальної мережі. Обмін інформацією між підбазами здійснюються з використанням каналів зв’язку. Як підбази розподіленої бази даних можуть використовуватись зосереджені (централізовані) бази даних і окремі (локальні) підбази. Обмін інформацією між взаємозв’язаними підбазами здійснюється головним чином результатною (обробленою, узагальненою) інформацією. При виконанні запиту в таких системах використовується декомпозиція запиту на підзапити до локальних підбаз і паралельне виконання виділених підзапитів у різних вузлах обчислювальної мережі. Ці бази даних мають безперечні переваги у порівнянні з централізованими: - обсяги пам’яті обмежені пам’ятю не однієї ЕОМ, а сумарною пам’ятю ЕОМ, які знаходяться в усіх вузлах мережі; - зменшуються затрати на передавання інформації, так як у кожному вузлі знаходиться та інформація, яка необхідна конкретному користувачу і по можливості забезпечує всі його інформаційні потреби. Однак розосереджена база даних призводить до неминучого дублювання деякої інформації, безконтрольності її зростання, а також значно ускладнюється проблема зберігання несуперечності інформації. Залежно від рівня підтримки різних типів локальних СКБД, розподілені СКБД поділяються на гомогенні (однорідні) та гетерогенні (різнорідні). В гомогенних системах усі вузли використовують один і той же тип СКБД. У різнорідних системах на вузлах можуть функціонувати різні типи СКБД, що використовують різні моделі даних, тобто різнорідна система може включати вузли з реляційними, мережевими, ієрархічними або об'єктно-орієнтованими СКБД. Однорідні системи значно простіше проектувати і супроводжувати. Крім того, подібний підхід дозволяє поетапно нарощувати розміри системи, послідовно додаючи нові вузли до вже існуючої розподіленої системи. Додатково з’являється можливість підвищувати продуктивність системи за рахунок організації на різних вузлах паралельної обробки інформації. Різнорідні системи зазвичай виникають в тих випадках, коли незалежні вузли, які вже експлуатують свої власні системи з базами даних, з часом інтегруються у новостворювану розподілену систему. У різнорідних системах для організації взаємодії між різними типами СКБД потрібно забезпечити перетворення переданих повідомлень. Для забезпечення прозорості щодо типу використовуваної СКБД користувачі кожного з вузлів повинні мати можливість формулювати запити мовою тієї СКБД, яка використовується на їх локальному вузлі. Система повинна взяти на себе пошук необхідних даних і виконання всіх необхідних перетворень переданих повідомлень. У загальному випадку дані можуть бути затребувані з іншого вузла, який характеризується такими особливостями: - інший тип використовуваного обладнання; - інший тип використовуваної СКБД; - інший тип застосовуваних обладнання та СКБД. Якщо використовується інший тип обладнання, але на вузлах застосовуються однакові СКБД, методи виконання перетворень цілком очевидні і включають заміну кодів і зміну довжини машинного слова. Якщо типи використовуваних на вузлах СКБД різні, процедура перетворення ускладнюється тим, що необхідно перетворювати структури даних однієї моделі даних в еквівалентні структури даних іншої моделі даних. Наприклад, відношення в реляційній моделі даних повинні бути перетворені в записи і набори, характерні для мережевої моделі даних. Крім того, доводиться транслювати текст запитів з однієї мови в іншу (наприклад, запити з оператором SELECT мови SQL може знадобитися перетворити в запити з операторами GET і FIND мови маніпулювання даними мережевої СКБД). Якщо відрізняються і тип використовуваного обладнання, і тип програмного забезпечення, то необхідно виконати обидва види трансляції. Все викладене вище надзвичайно ускладнює обробку даних в різнорідних розподілених СКБД. В гетерогенних системах може виникати проблема семантичної неоднорідності. Наприклад, атрибути, що мають у різних схемах одне і те ж ім’я, фактично можуть представляти абсолютно різні поняття. Аналогічно, атрибути з різними іменами фактично можуть представляти одну і ту ж характеристику. Типове рішення, що застосовується в деяких реляційних системах, полягає в тому, що окремі частини різнорідних розподілених систем повинні використовувати шлюзи, призначені для перетворення мови та моделі даних кожного з використовуваних типів СКБД в мову і модель даних реляційної системи. Однак підходу із застосуванням шлюзів властиві деякі серйозні обмеження. По-перше, шлюзи не дозволяють організувати систему управління транзакціями навіть для окремих пар систем. Іншими словами, шлюз між двома системами представляє собою не більш ніж транслятор запитів. Також шлюзи не дозволяють системі координувати управління паралельним виконанням та процедурами відновлення транзакцій, які включають оновлення даних в обох базах. По-друге, використання шлюзів дозволяє вирішити лише завдання трансляції запитів з мови однієї СКБД на мову іншої. Тому вони, як правило, не дозволяють вирішити проблему створення однорідної структури і усунути відмінності між представленнями даних у різних схемах. Для подолання проблем гетерогенних систем комітет Open Group організував робочу групу (Specification Working Group – SWG), покликану підготувати специфікації, що регламентують інфраструктуру середовища бази даних, яка включає такі елементи: - уніфікований і досить потужний інтерфейс мови SQL (SQL API), який дозволяє створювати клієнтські програми таким чином, щоб вони не були прив’язані до конкретного типу використовуваної СКБД; - уніфікований протокол доступу до бази даних, що дозволяє безпосередньо взаємодіяти СКБД різних типів без необхідності використання будь-якого шлюзу; - уніфікований мережевий протокол, що дозволяє здійснювати взаємодію СКБД різних типів. Найважливішим завданням цієї групи слід вважати пошук способу, який дозволяє в одній транзакції виконувати обробку даних, що містяться в декількох базах, керованих СКБД різних типів, причому без необхідності застосування будь-яких шлюзів.
3.1.4 Переваги та недоліки систем керування розподіленими базами даних
Система керування розподіленою БД порівняно з традиційними системами має ряд переваг: - дані розташовуються близько до найзатребуванішого вузла. Дані в розподіленій БД розміщуються на тому вузлі, де в них є найбільша потреба; - високий ступінь локальної автономності. Користувачі, які найчастіше працюють з даними на деякому локальному вузлі можуть здійснювати локальний контроль над необхідними їм даними, встановлювати або регулювати локальне обмеження на їх використання. Адміністратор глобальної бази даних (АБД) відповідає за систему в цілому. Як правило, частина цієї відповідальності делегується на локальний рівень, завдяки чому АБД локального рівня отримує можливість управляти локальною СКБД; - швидкий доступ до даних. Кінцеві користувачі часто працюють тільки з деякою підмножиною даних компанії. При цьому підмножина може зберігатися локально, і система бази даних забезпечить більш оперативний доступ до даних, ніж централізована БД, де дані зберігаються віддалено; - підвищення продуктивності. В розподіленій БД має місце розпаралелення процесів обробки даних. Оскільки кожен вузол працює лише з частиною бази даних, то ступінь використання центрального процесора та служб введення-виведення може виявитися нижчим, ніж у випадку централізованої БД; - підвищення надійності та доступності даних. У централізованих СКБД відмова центрального комп'ютера приведе до припинення функціонування всієї СКБД. На відміну від них, розподілена СКБД дозволяє перемісити операції з вузла, що вийшов з ладу, на інший. Навантаження системи розподіляється між іншими робочими станціями, оскільки, завдяки реплікації, дані зберігаються на декількох вузлах; - модульність системи. Розширення розподіленої бази даних відбувається шляхом додавання до мережі нового вузла, який не впливає на функціонування вже існуючих вузлів. В централізованих СКБД розширення бази даних може вимагати заміни обладнання та програмного забезпечення; - зменшення вартості організації і витрат на експлуатацію баз даних. У 1960-ті роки потужність обчислювальних засобів зростала пропорційно квадрату вартості її устаткування, тому система, вартість якої була втричі вища за вартість даної, перевершувала її за потужністю у дев'ять разів. Ця залежність отримала назву закону Гроша. Однак сьогодні вважається загальноприйнятим положення, згідно з яким набагато дешевше зібрати з невеликих комп'ютерів систему, потужність якої буде еквівалента потужності одного великого комп'ютера (мейнфрейма). Виявляється, що значно вигідніше встановлювати в підрозділах організації власні малопотужні комп'ютери та додавати в мережу нові робочі станції, ніж модернізувати систему з мейнфреймом. В багатьох корпораціях на мейнфреймах виконують лише вузькоспеціалізовані задачі, а всі інші – на персональних комп’ютерах; - зменшення вартості передачі даних. Вартість передачі даних через комп’ютерну мережу є відносно високою порівняно з локальним доступом до даних. Вона визначається не лише кількістю переданих бітів інформації, а й витратами на підтримку багаторівневого мережевого протоколу, який управляє підготовкою інформаційних пакетів до передачі і збором отриманих пакетів на вузлі-приймачі. Реалізація кожного рівня протоколу вимагає значних обчислювальних витрат. У розподіленій СКБД забезпечується можливість розмістити дані на тому вузлі, де в них є найбільша потреба і обробляти їх локально; - незалежність від вузла обробки даних. Кінцевий користувач отримує доступ до будь-якої наявної копії даних, а запит кінцевого користувача обробляється будь-яким вузлом в місці розташування даних. Іншими словами, запит не залежать від конкретного вузла обробки даних: будь-який доступний вузол може обробити запит користувача; - збільшення обсягу збережених і доступних для обробки даних. Обсяг даних не обмежується об’ємом пам’яті мейнфрейма. Перевантаження через збільшення розміру бази даних зазвичай усуваються шляхом додавання до мережі нових обчислювальних потужностей і пристроїв зовнішньої пам'яті; - зменшення обсягів даних, які пересилаються. Досягається завдяки тому, що частина даних зберігається і обробляється локально. На жаль, сучасні розподілені СКБД мають ряд недоліків: - складність управління і контролю. Управління розподіленими даними – більш важке завдання, ніж управління централізованими даними. Додатки повинні визначати місцезнаходження даних і вміти потім зв'язувати в єдине ціле інформацію, отриману з різних місць. Адміністратори БД повинні мати можливість координувати дії бази даних, щоб запобігти погіршенню якості БД через аномалії даних. Особливу увагу слід приділяти управлінню транзакціями, паралельному виконанню, безпеці, резервному копіюванню, реплікації даних, відновленню процесів, оптимізації запитів, вибору шляхів доступу і т. д; - ускладнення процедури розробки розподіленої БД. Розробка розподілених баз даних, вимагає прийняття рішення про фрагментацію даних, розподіл фрагментів по окремим вузлам і реплікацію даних; - безпека. В централізованих системах доступ до даних легко контролюється. В розподілених системах відповідальність за управління даними розподіляється між різними людьми, що знаходяться в різних місцях, а локальні мережі все ще залишаються уразливими у відношенні безпеки; - недостатня стандартизація. Незважаючи на те, що розподілені бази даних залежать від ефективності комунікацій, поки не існує стандартного протоколу обміну інформацією на рівні баз даних (хоча TCP/IP є фактично стандартним протоколом на рівні мереж, відсутній стандарт протоколу на рівні додатків). Відсутність стандартів істотно обмежує потенційні можливості розподілених СКБД. Крім того, не існує інструментальних засобів і методологій, здатних допомогти користувачам перетворити централізовані системи в розподілені; - складність управління середовищем даних. Організувати доступ до диска і зберігання даних у розподіленому середовищі складніше, ніж в централізованій системі, тому управління таким середовищем даних стає більш складним у відношенні як людських ресурсів, так і програмного забезпечення; - підвищення вартості навчання. Вартість навчання в розподіленій моделі, як правило, вище, ніж в централізованій, і часто порівнюється з вартістю обладнання; - нестача досвіду. Ще не накопичено достатньо досвіду промислової експлуатації розподілених систем. Таке становище є значним стримуючим фактором для потенційних прихильників розподіленої технології; - підвищені вимоги до умов зберігання даних. У розподілених БД декілька копій даних необхідно розміщувати на декількох сайтах, що вимагає додаткових ресурсів (місце на жорсткому диску). Цей недолік не є дуже істотним, оскільки вартість зберігання інформації на жорстких дисках швидко зменшується. Сьогодні розподілені БД з успіхом експлуатуються, однак гнучкість і потужність, якими вони теоретично володіють, використовується не в повній мірі. Властива розподіленим базам даних складність вимагає невідкладної розробки стандартів на протоколи управління транзакціями, паралельного виконання, безпеки, резервного копіювання і відновлення, оптимізації, вибору шляхів доступу і т. д.
3.1.5 Принципи створення розподілених БД
Фундаментальний принцип створення розподілених баз даних («правило 0») передбачає їх організацію таким чином, щоб для користувача розподілені системи виглядали так само, як і нерозподілені. З фундаментального принципу витікають додаткові правила, запропоновані К.Дейтом: 1. Незалежність локального вузла. Кожний локальний вузол може працювати як незалежна, або автономна СКБД. Всі операції на вузлі контролюються цим вузлом: безпека, управління паралельним виконанням, резервне копіювання і відновлення даних. 2. Незалежність від центрального вузла. Всі вузли мають рівні можливості. Жодний вузол в мережі не повинен звертатись до «центрального» вузла з метою отримання певного централізованого сервісу. 3. Незалежність від збоїв. Функціонування системи не залежить від збою на якомусь вузлі. Система продовжує виконання операцій навіть при несправності вузла або при розширенні мережі. 4. Прозорість місця розташування. Користувачу не потрібно знати фізичне місце розташування даних, щоб здійснити їх пошук. Користувач працює з даними так, ніби вони розташовані на його локальному вузлі. 5. Прозорість фрагментації. Користувачу не потрібно знати імена фрагментів БД, щоб отримати доступ до них. Користувач бачить єдину логічну базу даних. 6. Прозорість реплікації. Для користувачів повинно бути створено таке середовище, щоб вони могли вважати, що в дійсності дані не дублюються. Тобто, користувачу не потрібно мати відомості про існуючі копії фрагментів. 7. Розподілена обробка запитів. Для обробки запиту може знадобитись звернення до декількох вузлів. В розподіленій системі може існувати багато способів пересилання даних для виконання цього запиту. СУРБД повинна виконати оптимізацію запиту прозоро для користувача. 8. Управління розподіленими транзакціями. Транзакції можуть оновлювати дані на декількох різних вузлах. Виконання транзакцій відбувається прозоро для користувача. 9. Апаратна незалежність. Система повинна виконуватись на різних апаратних платформах. 10. Незалежність від операційної системи. Система повинна виконуватись в будь-якій операційній системі. 11. Незалежність від мережі. Можливість підтримувати багато типів комунікаційних мереж. 12. Незалежність від типу бази даних. Необхідно, щоб екземпляри БД на різних вузлах всі разом підтримували один і той же інтерфейс, і зовсім необов'язково, щоб це були копії однієї і тієї ж версії БД. Іншими словами, розподілені бази даних можуть бути неоднорідними. На сьогодні жодна з розподілених баз даних не відповідає усім наведеним правилам, однак правила Дейта повністю описують розподілені бази даних і відіграють важливу роль при їх розробці.
|
|
Пєтух А.М., Романюк О.В., Романюк О.Н. ВНТУ 2016 |