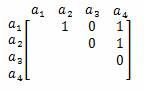|
БАЗИ ДАНИХ. МОВИ ЗАПИТІВ, УПРАВЛІННЯ ТРАНЗАКЦІЯМИ, РОЗПОДІЛЕНА ОБРОБКА ДАНИХ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
3.2 Проектування розподіленої БД
3.2.1 Фрагментація даних
При проектуванні розподіленої БД виникають три нові проблеми. - Як розбивати базу даних на фрагменти? - Які фрагменти необхідно дублювати (реплікувати або тиражувати)? - Де розташувати ці фрагменти і репліки? Фрагментація даних і реплікація даних відносяться до перших двох зазначених проблем, а розміщення даних – до третьої. Визначення та розміщення фрагментів повинно відбуватись з урахуванням особливостей використання бази даних. Зокрема, необхідно проводити аналіз транзакцій та запитів. Згідно з емпіричним правилом Парето доцільно проводити аналіз лише 20% найбільш активних запитів користувачів, оскільки вони створюють 80% навантаження на базу даних. Для визначення того, які з транзакцій підлягають детальному аналізу, можна скористатися таблицею відповідності транзакцій і відношень, в якій показані відношення, доступ до яких відбувається при виконанні кожної транзакції, а також діаграмою частоти виконання транзакцій, яка схематично показує відношення, вірогідність використання яких в транзакціях є найбільшою. Проектування повинно проводитись на основі як кількісних, так і якісних показників. Кількісна інформація використовується як основа для розміщення, а якісна слугує базою при створенні схем фрагментації. Кількісна інформація включає такі показники: - частота виконання транзакції; - вузол, на якому виконується транзакція; - вимоги до продуктивності транзакцій. Якісна інформація може містити відомості про виконувані транзакції: - використовувані відношення, атрибути та рядки; - тип доступу (читання або запис); - предикати операцій читання. Визначення та розміщення фрагментів по вузлах виконується для досягнення п’яти основних стратегічних цілей. 1. Локалізація посилань. Всюди, де це можливо, дані повинні зберігатись якомога ближче до місць їх використання. Якщо фрагмент використовується на декількох вузлах, то може виявити доцільним розмістити на них його копії (репліки). 2. Підвищення надійності та доступності. Надійність та доступність даних підвищується за рахунок використання механізму реплікації. У випадку відмови одного з вузлів завжди буде існувати копія фрагмента, яка зберігається на іншому вузлі. 3. Задовільний рівень продуктивності. Невірне розміщення фрагментів може призвести до виникнення вузьких місць в системі. У цьому випадку деякий вузол буде перевантажений запитами від інших вузлів, що суттєво може знизити продуктивність всієї системи. В той же час неправильне розміщення може призвести до неефективного використання ресурсів системи. 4. Компроміс між ємністю та вартістю зовнішньої пам’яті. Всюди, де це можливо, рекомендовано використовувати дешеві пристрої масової пам’яті. Ця вимога повинна бути узгоджена з вимогою забезпечення локалізації посилань. 5. Мінімізація витрат на передачу даних. Варто ретельно враховувати вартість виконання в системі віддалених запитів. Витрати на вибірку будуть мінімальними при забезпеченні максимальної локалізації посилань, тобто тоді, коли кожен вузол буде мати свою власну копію необхідних йому даних. Однак при оновленні даних реплікованих даних внесені зміни необхідно буде поширити на всі вузли, які мають копію оновленого відношення, що збільшить витрати на передачу даних.
Фрагментація даних допускає розбиття одного об'єкта на два або більше сегментів чи фрагментів. Об'єкт може являти собою користувацьку базу даних, системну базу даних або таблицю. Кожен фрагмент може зберігатися на будь-якому вузлі комп'ютерної мережі. Інформація про фрагментацію даних зберігається в каталозі розподілених даних (distributed data catalog, DDC), до якого процесор транзакцій (TP) може отримати доступ при обробці запитів користувача. Необхідність у фрагментації зумовлена рядом причин: - умови використання. Найчастіше програми працюють з деякими представленнями, а не з повними базовими відношеннями. Тому з точки зору розміщення даних доцільніше організувати роботу додатків з певними підмножинами відношень, які розглядаються як мінімальна одиниця розміщення; - ефективність. Дані зберігаються в тих місцях, де вони найчастіше використовуються. Крім того, виключається необхідність зберігання даних, які не використовуються локальними додатками; - паралельність. Оскільки фрагменти є мінімальними одиницями розміщення, транзакції можуть бути розділені на декілька підзапитів, що звертаються до різних фрагментів. Такий підхід дає можливість підвищити рівень паралельності обробки в системі, тобто дозволяє транзакціям, які допускають це, ефективно виконуватися в паралельному режимі. - захищеність. Дані, які не використовуються локальними додатками, не зберігаються на вузлах, і відповідно, користувачі, які не володіють відповідними правами, не зможуть отримати до них доступ. В розподіленій системі можливі три види фрагментації даних: горизонтальна, вертикальна і змішана. Зазначені види фрагментації даних діють на рівні таблиць і полягають у розбитті таблиці на логічні фрагменти. При проведенні фрагментації необхідно дотримуватись трьох правил. 1. Повнота. Якщо екземпляр відношення R розбивається на фрагменти, наприклад R1, R2, … Rn, то кожний елемент даних, присутній у відношенні R, має міститися, принаймні, в одному зі створених фрагментів. Виконння цього правила гарантує, що жодні дані не будуть втрачені в результаті виконання фрагментації. 2. Відновлюваність. Повинна існувати операція реляційної алгебри, яка дозволила б відновити відношення R з його фрагментів. Це правило гарантує збереження функціональних залежностей. 3. Відсутність перетинань. Якщо елемент даних міститься у фрагменті R1, то він не повинен одночасно бути присутнім в будь-якому іншому фрагменті. Виключенням з цього правила є операція вертикальної фрагментації, оскільки в цьому випадку в кожному фрагменті повинні бути присутні атрибути первинного ключа, необхідні для відновлення вихідного відношення. Це правило гарантує мінімальну надлишковість даних у фрагментах. У випадку горизонтальної фрагментації елементом є рядок, а у випадку вертикальної фрагментації – атрибут.
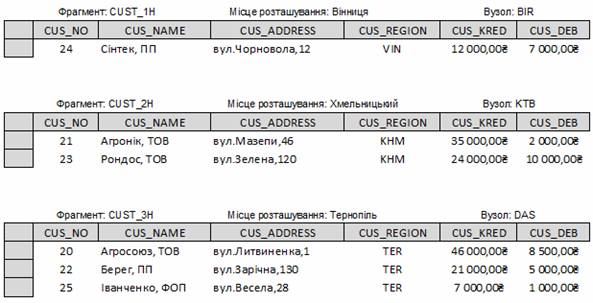
Горизонтальна фрагментація. При горизонтальній фрагментації розбиття таблиці (відношення) відбувається за рахунок розміщення в окремій таблиці з однаковою структурою унікальних (не перекриваються) груп рядків (кортежів). Фактично здійснюється зберігання рядків однієї логічної таблиці в декількох ідентичних фізичних таблицях на різних вузлах. Кожен фрагмент зберігається на окремому вузлі і кожен фрагмент має унікальні рядки. Однак всі унікальні рядки мають однакові атрибути (стовпці). Інакше кажучи, кожен фрагмент еквівалентний оператору SELECT з модифікуючим виразом WHERE по єдиному атрибуту. Нехай компанія «Геліос» має представництва у Вінниці (VIN), Хмельницькому (KHM) та Тернополі (TER). Керівництву необхідна інформація про клієнтів по всім трьом містам, але кожному підрозділу компанії необхідна інформація лише по своїм локальним клієнтам. Враховуючи це, доцільним є розподіл даних по містах з використанням горизонтальної фрагментації (табл. 3.1).
Таблиця 3.1 – Горизонтальна фрагментація таблиці CUSTOMERS по містах
Кожний горизонтальний фрагмент може мати довільну кількість рядків, але повинен мати такі ж атрибути, що й інші фрагменти. Після фрагментації будуть створені три таблиці, показані на рис. 3.5. В одних випадках доцільність використання горизонтальної фрагментації цілком очевидна, а в інших випадках потрібне виконання детального аналізу додатків. Цей аналіз повинен включати перевірку предикатів (або умов) пошуку, які використовуються у транзакціях або запитах, що виконуються в додатку. Предикати можуть бути простими ( включають один атрибут) та складними (включають декілька атрибутів). Для кожного з використовуваних атрибутів предикат може містити єдине значення або декілька значень. В останньому випадку значення можуть бути дискретними або входити в діапазон значень.
Рисунок 3.5 – Фрагменти таблиці по місцю розташування
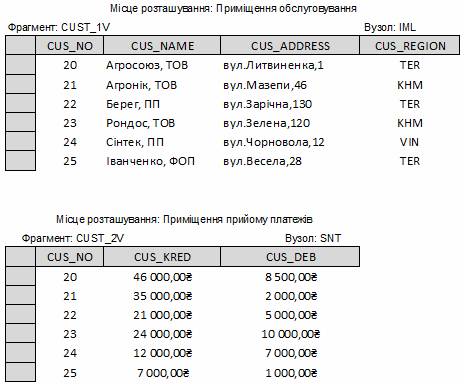
Стратегія визначення типу фрагментації передбачає пошук набору мінімальних (тобто повних і релевантних) предикатів, які можна використовувати як основу для створення схеми фрагментації. Набір предикатів є повним тоді і тільки тоді, коли ймовірність звернення до будь-яких двох рядків одного і того ж фрагмента з боку будь-якої транзакції однакова. Предикат є релевантним, якщо існує, принаймні, одна транзакція, яка по-різному звертається до виділених за допомогою цього предиката фрагментів. Вертикальна фрагментація. Такий тип фрагментації передбачає поділ таблиці (відношення) на підмножини стовпців (атрибутів). Кожний фрагмент зберігається на окремому вузлі і має унікальні стовпці – за винятком ключового стовпця, який є у всіх фрагментах. Це еквівалентно застосуванню оператора PROJECT. Нехай у компанії є два відділи: відділ обслуговування і відділ прийому платежів. Кожний відділ розташований в різних будівлях і кожному відділу потрібна інформація лише по декільком атрибутам таблиці CUSTOMERS. У цьому випадку доцільно виконати вертикальну фрагментацію (табл.3.2).
Таблиця 3.2 – Вертикальна фрагментація таблиці CUSTOMERS по атрибутах
Кожний вертикальний фрагмент має однакову кількість рядків, але включає в себе різні атрибути і спільний для усіх фрагментів ключовий атрибут. Результати вертикальної фрагментації наведено на рис.3.6.
Рисунок 3.6 – Вміст таблиць при вертикальній фрагментації
При формуванні вертикальних фрагментів необхідно враховувати сполучуваність атрибутів один з одним. Один із способів визначення сполучуваності атрибутів полягає у створенні матриці, яка містить кількість звернень до кожної пари атрибутів. Наприклад, транзакція, яка здійснює доступ до атрибутів а1, а2 і а4 відношення R, що складається з набору атрибутів (a1, a2, а3, а4), може бути представлена такою матрицею:
Ця матриця є трикутною; її діагональ не заповнюється, а нижня частина є дзеркальним відображенням верхньої частини і тому може не розглядатися. Одиниці в матриці означають наявність доступу із зверненням до відповідної пари атрибутів і, в кінцевому рахунку, повинні бути замінені числами, що відображають частоту виконання транзакції. Подібна матриця складається для кожної транзакції, після чого створюється загальна матриця, яка містить суми всіх показників доступу до кожної з пар атрибутів. Пари атрибутів з високим показником сполучуваності повинні бути присутніми в одному і тому ж вертикальному фрагменті. Пари з невисоким показником сполучуваності можуть бути розподілені по різним вертикальним фрагментами. Очевидно, що обробка відомостей про окремі атрибути для всіх найважливіших транзакцій може потребувати багато часу і обчислень. Тому, якщо дані про сполучуваність певних атрибутів заздалегідь накопичені, може виявитися доцільним обробляти відомості відразу про групи атрибутів. Подібний підхід носить назву розщеплення (splitting) і вперше був запропонований в 1984 році. Він дозволяє виділити набір фрагментів, які гарантовано будуть відповідати правилу відсутності перетинань. Фактично вимога відсутності перетинань стосується лише атрибутів, що не входять в первинний ключ відношення. Атрибути первинного ключа повинні бути присутніми в кожному з виділених вертикальних фрагментів, тому можуть не розглядатися при аналізі. Змішана фрагментація. Змішана фрагментація являє собою комбінацію вертикальної і горизонтальної фрагментацій. Іншими словами, таблиця може поділятися на кілька горизонтальних множин (рядків), кожна з яких поділяється на безліч атрибутів (стовпців).
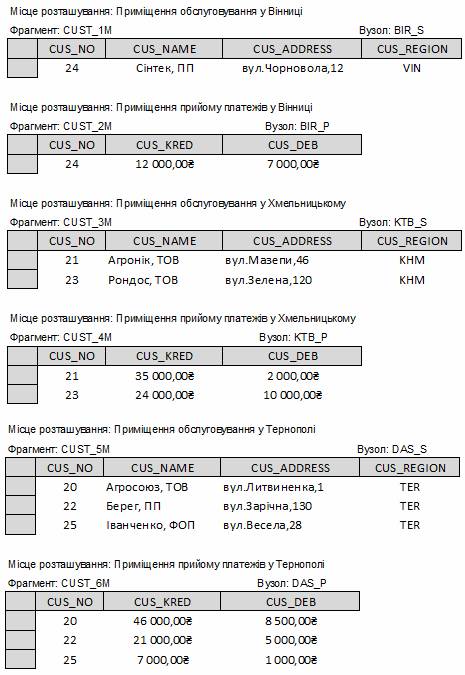
Таблиця 3.3 – Змішана фрагментація таблиці CUSTOMERS
Припустимо, що структура компанії «Геліос» вимагає, щоб дані таблиці CUSTOMERS були фрагментовані горизонтально, відображаючи поділ компанії на представництва, і в той же час в межах представництва дані необхідно фрагментувати вертикально, щоб виділити відділи обслуговування і прийому платежів. В цьому випадку необхідно виконати змішану фрагментацію. Спочатку потрібно провести горизонтальну фрагментацію на кожному вузлі на основі розбиття компанії по представництвам (CUS_REGION). В результаті отримаємо набір кортежів клієнтів (горизонтальні фрагменти), які розташовані на різних вузлах. Оскільки відділи розташовані в різних приміщеннях, необхідно виконати вертикальну фрагментацію в межах кожного горизонтального фрагмента для розбиття атрибутів, що забезпечить кожне представництво необхідною йому інформацією. Результати змішаної фрагментації наведено в талб.3.3. Кожний фрагмент в табл.3.3 містить дані клієнтів по регіону, в межах кожного регіону – по локальним відділам. Таблиці, які утворено внаслідок змішаної фрагментації, показано на рис.3.7.
Рисунок 3.7 – Вміст таблиць після змішаної фрагментації
Механізму фрагментації притаманні два основних недоліки: - продуктивність. Продуктивність глобальних додатків, які потребують доступу до даних з декількох фрагментів, розташованих на різних вузлах, може виявитися нижче, ніж локальних; - цілісність даних. Підтримка цілісності даних може істотно ускладнюватися, оскільки функціонально залежні дані можуть зробитися фрагментованими і розміщуватися на різних вузлах. Від фрагментації варто відмовитись у випадку, коли відношення містить невелику кількість рядків, які оновлюються відносно рідко. В такому випадку краще розмістити копію такого відношення на кожному з вузлів мережі.
Реплікація (тиражування) даних (Data Replication) – це механізм синхронізації вмісту декількох копій фрагментів розподіленої БД. Під реплікацією слід розуміти асинхронний переніс змін об’єктів вихідної бази даних (source database) в бази даних, що належать різним вузлам розподіленої системи. Можливі три варіанти реплікації БД: - повністю реплікована БД: зберігає копії одного й того ж фрагмента БД на всіх вузлах мережі. В даному випадку всі фрагменти БД репліковані. Така БД може виявитися не зручною у використанні через великі витрати. - частково реплікована БД: зберігає копії одного й того ж фрагмента БД на декількох вузлах мережі (рис.3.8). Більшість СУРБД допускають роботу саме з частково реплікованою БД. - нереплікована БД: зберігає кожний фрагмент БД на окремому вузлі. В цьому випадку дубльовані фрагменти БД відсутні.
Рисунок 3.8 – Часткова реплікація даних
На реплікацію вливають декілька факторів: - розмір БД; - частота використання БД; - витрати (ефективність, непродуктивні витрати програмного забезпечення та управління), пов'язані з синхронізацією транзакцій та їх частин при забезпеченні належної відмовостійкості, пов'язаної з реплікацією даних. Якщо частота звернення до віддалених даних дуже висока, а база даних велика, то реплікація даних може зменшити витрати на обробку запитів. Інформація про реплікацію даних зберігається в каталозі розподілу даних (DDC), вміст якого TP використовує, щоб прийняти рішення – до якої копії фрагмента БД необхідно забезпечити доступ. Реплікація даних дозволяє відновити загублені дані. При реплікації даних потрібно дотримуватись правила взаємної несуперечності, згідно з яким всі копії фрагменту повинні бути ідентичні (визначення та склад даних у всіх копіях повинні бути однаковими). Для забезпечення несуперечності даних в репліках СУРБД повинна гарантувати своєчасне оновлення БД на всіх вузлах, де є репліки даних. Ці функції виконує спеціальний модуль СУРБД – сервер тиражування даних, який називають реплікатором (replicator). Реплікатор повинен вирішувати чотири основні задачі: - Що тиражувати? - Де тиражувати? - Коли тиражувати? - Як вирішувати можливі конфлікти? Розглянемо детальніше кожну із зазначених задач.
Що тиражувати?
Ключовим поняттям у процесі тиражування є поняття узгодженого розподіленого набору даних (consistent distributed data set - CDDS). Це набір даних в базі (або база повністю), ідентичність яких підтримується реплікатором у всіх вузлах, залучених до процесу тиражування. CDDS може бути представлений такими конфігураціями даних: - вся база даних; - обрані об’єкти бази даних: таблиці або представлення; - вертикальні фрагменти БД; - горизонтальні фрагменти БД; - поєднання наборів 2-4. Набір даних буде вважатись CDDS лише у випадку дотримання таких мов: 1. Набір даних повинен розташовуватися в декількох базах даних в ідентичних копіях. Ідентичність тут розуміється як однаковість визначення та складу даних. 2. Дані з різних CDDS повинні бути взаємно ортогональні, тобто одні й ті ж дані не можуть входити до різних CDDS. 3. CDDS повинен мати властивість повноти, тобто включати всі ідентичні копії даних, що існують в розподіленій системі. Узгодженість CDDS автоматично підтримується реплікатором і проявляється в тому, що: - будь-яка зміна будь-якої копії CDDS автоматично поширюється на всі інші копії; - усередині CDDS жодна копія даних не має переваги перед іншою копією – вони абсолютно рівноправні. - всі об'єкти, що становлять кожну копію CDDS, мають однакові імена. Принципово є те, що всі вузли є рівноправними, а тому можуть бути як джерелами, так і приймачами змін, хоча за необхідності всередині CDDS визначається пріоритет даних кожного вузла, який використовується при автоматичному вирішенні конфліктів в тиражованих даних.
Де тиражувати?
Ще одним важливим елементом тиражування є шлях перенесення змін (data propagation path - DPP), відповідно до якого реплікатор передає дані з кожної тиражованої бази даних в інші БД. Гнучкість тиражування в значній мірі забезпечується великим вибором способів передачі даних між вузлами розподіленої системи. Розрізняють такі схеми тиражування даних, реалізовані реплікатором: 1. «Центр-філії», зміни до БД філій переносяться в центральну БД, та/або навпаки. 2. Рівноправне, кілька БД поділяють загальний набір змінюваних і тиражованих даних. 3. Каскадне, зміни в одній БД переносяться в іншу БД, звідки у свою чергу в третю БД і т. д., ця схема дозволяє оптимізувати баланс завантаження серверів баз даних, розташованих на різних вузлах. 4. Через шлюзи зміни в базі даних можуть переноситися в БД іншої СКБД. 5. Різні комбінації всіх перерахованих вище схем. В основі описаних схем лежать механізми, що регулюють взаємини між залученими в процес тиражування вузлами (з точки зору приймаючого вузла): 1. «Рівний-з-рівним» (peer-to-peer або full peer): всі зміни, виконані з CDDS на першому вузлі, потраплять на другий вузол і навпаки, виконується контроль можливих колізій. 2. Доступ з виявленням і розв'язанням конфліктів (protected read): зміни з першого вузла потрапляють на другий, проводиться контроль можливих конфліктів (наприклад, якщо джерел декілька); зміни CDDS на другому вузлі незаконні, ігноруються і на перший вузол не передаються. 3. Доступ з читанням без попередження конфліктів: те ж саме, що і 2, але конфлікти не виявляються і не вирішуються. 4. Доступ через шлюз: те ж саме, що і 3, але другий вузол містить дані, одержувані через шлюз до БД іншої СКБД, при цьому використовується мова запитів OpenSQL.
Коли тиражувати?
Елементарною зміною, яка викликає реакцію реплікатора, є транзакція. Тиражувати кожну транзакцію по одинці було б не завжди зручно. Тому, для досягнення максимальної гнучкості, реплікатор надає такі можливості: - тиражування починається після завершення певного числа транзакцій, в тому числі і після кожної транзакції; - тиражування відбувається через рівні проміжки або до певного моменту часу; - процес тиражування контролюється вручну адміністратором системи або створеним користувачем монітором.
Як вирішувати можливі конфлікти?
Конфлікти, що виникають в деяких ситуаціях, наприклад, при зустрічному тиражуванні або при відновленні бази даних за допомогою реплікатора з реплікованої копії, можна віднести до розряду планованих проблем. Реплікатор за необхідності самостійно виявляє протиріччя в тиражованих даних і надає адміністратору можливість вирішення конфлікта (суперечливі дані обов'язково реєструються в журналі), або робить це автоматично. Можливі такі варіанти: - вирішення конфлікту на користь більш ранньої або більш пізньої зміни; - вирішення конфлікту на користь найвищого пріоритету тиражованого запису. Загалом при роботі з базою даних СКРБД повинна виконувати такі процеси: - якщо БД фрагментована, то СКРБД для отримання доступу до відповідного фрагмента повинна розбивати запит на підзапити; - якщо БД реплікована, то СКРБД повинна прийняти рішення, до якої копії необхідно забезпечити доступ. Операція читання (Read) обирає найближчу копію, яка придатна для даної транзакції. Операція запису (Write) у відповідності з правилом взаємної несуперечності повинна вибирати і оновлювати всі копії даних; - процесор транзакцій (ТР) надсилає дані на обробку на кожний обраний процесор даних (DP); - DP отримує дані, обробляє запит і відсилає дані назад на ТР; - ТР об’єднує всі відповіді DP. Технологія реплікації даних дозволяє зменшити загальні витрати на комунікації і виконання запитів, оскільки копії фрагментів підвищують рівень доступності даних та зменшують час відгуку. До основних переваг цієї технології можна віднести: 1. Дані завжди розташовані там, де вони обробляються. Це дозволяє істотно збільшити швидкість доступу до них. 2. Передаються лише операції, які змінюють дані, що в асинхронному режимі дозволяє значно зменшити трафік. 3. З боку вихідної БД для приймаючих БД реплікатор постає як процес, ініційований одним користувачем, тоді як у фізично розподіленому середовищі з кожним локальним сервером працюють всі користувачі розподіленої системи, конкуруючи за ресурси один з одним. 4. Жоден тривалий збій зв'язку неспроможний порушити передачу змін. Це пояснюється тим, що тиражування передбачає буферизацію потоку змін (транзакцій) і після відновлення зв'язку передача відновлюється з тих транзакцій, на яких тиражування було перервано. Серед недоліків технології тиражування даних можна виділити неможливість цілковитого виключення конфліктів між двома версіями одного й того ж запису. Вони виникатимуть, коли внаслідок асинхронності передачі два користувача на різних вузлах виправлять один і той самий запис в той момент, коли зміни даних із першої бази даних ще не були перенесені на другу. Отже, під час проектування розподіленого середовища за допомогою технології тиражування даних слід передбачити конфліктні ситуації та запрограмувати реплікатор на будь-який варіант їх вирішення.
Розміщення даних (data allocation) – це процес прийняття рішення про місце зберігання даних. Виділяють чотири альтернативні стратегії розміщення даних. Централізоване розміщення. Дана стратегія передбачає створення на одному з вузлів єдиної бази даних під управлінням СКБД, доступ до якої будуть мати всі користувачі мережі (ця стратегія відома під назвою «розподілена обробка»). В цьому випадку локалізація посилань мінімальна для всіх вузлів, за виключенням центрального, оскільки для отримання будь-якого доступу до даних необхідне встановлення мережевого з’єднання. Тому рівень витрат на передачу даних досить високий. Рівень надійності та доступності в системі низький, оскільки відмова на центральному вузлі призведе до порушення роботи всієї системи. Секційне (роздільне, фрагментоване) розміщення. База даних розбивається на декілька фрагментів, кожний з яких зберігається на одному з вузлів системи. Якщо кожний елемент даних буде розміщений на тому вузлі, на якому він найчастіше використовується, то рівень локалізації посилань буде високий. За відсутності реплікації вартість зберігання даних буде мінімальна, але при цьому рівень надійності та доступності даних в системі буде невисокий. Однак він вищий, ніж в попередньої стратегії, оскільки відмова на будь-якому з вузлів спричинить припинення доступу лише до тих даних, які на ньому зберігались. За правильного способу розміщення даних можна досягти високого рівня продуктивності та низького рівня витрат на передачу даних. Розміщення з повною реплікацією. Згідно з цією стратегією на кожному з вузлів системи розміщується повна копія всієї бази даних. Локалізація посилань, надійність та доступність даних, рівень продуктивності системи будуть максимальними. Однак високими будуть вартість пристроїв зберігання інформації та витрати на передачу інформації про оновлення. Для подолання частини цих проблем в деяких випадках використовують технологію знімків. Під знімком розуміють копію бази даних в деякий момент часу. Ці копії оновлюються через деякий встановлений інтервал часу, наприклад один раз в годину або в тиждень, тому вони не завжди актуальні в поточний момент. Іноді в розподілених системах знімки використовуються для реалізації представлень, що дозволяє покращити час виконання в базі даних операцій з представленнями. (дет. 23.6 Конноли) Розміщення з вибірковою реплікацією. Дана стратегія є комбінацією методів фрагментації, реплікації та централізації. Одні масиви даних розбиваються на фрагмента, що дозволяє досягти для них високого рівня локалізації посилань. В той же час, інші масиви даних, які не підлягають частим оновленням, але використовуються на багатьох вузлах, реплікуються. Всі інші дані зберігаються централізовано. Дана стратегія об’єднує переваги перших трьох стратегій та виключає їх недоліки. Завдяки своїй гнучкості ця стратегія використовується найчастіше. В табл. 3.4 наведено зведені характеристики розглянутих стратегій розміщення даних. Інформація про схеми фрагментації, реплікації та розміщення міститься в глобальному системному каталозі. Каталог може бути організований у вигляді розподіленої бази даних і тому також може підлягати фрагментації та розміщуватися на різних вузлах, повністю реплікуватися або розміщуватися централізовано.
Таблиця 3.4 – Порівняльна характеристика стратегій розміщення даних
3.2.4 Методологія проектування розподілених БД
Методологія проектування розподілених баз даних включає шість основних етапів. 1. Розробити проект для глобальних відносин. 2. Провести дослідження топології системи. Наприклад, визначити, чи повинно бути передбачено застосування бази даних в кожному підрозділі компанії, в кожному місті або регіоні. У першому варіанті може виявитися найбільш доцільною фрагментація відношень за номером підрозділу. А в останніх двох варіантах найбільш прийнятне рішення може передбачати фрагментацію відношень з урахуванням того, чи відносяться дані до певного міста чи регіону. 3. Проаналізувати найбільш важливі транзакції в системі і визначити, за яких умов може знадобитися горизонтальна або вертикальна фрагментація. 4. Прийняти рішення про те, які відношення не слід фрагментувати; копії таких відношень повинні бути розподілені по всіх вузлах. З глобальної ER-діаграми видалити відношення, які не повинні бути фрагментовані, а також зв’язки, в яких беруть участь виконувані на них транзакції. 5. Провести дослідження відношень, які знаходяться на стороні «один» зв’язку «один до багатьох», і вибрати найбільш прийнятну схему фрагментації для цих відношень з урахуванням топології системи. Відношення, які перебувають на стороні «багато» зв’язку «один до багатьох», можуть виявитися найбільш підходящими для похідної фрагментації. 6. За результатами виконання попереднього етапу визначити необхідність введення додаткової вертикальної або змішаної фрагментації (тобто визначити, чи є такі транзакції, для яких потрібен доступ до підмножини атрибутів відношення).
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Пєтух А.М., Романюк О.В., Романюк О.Н. ВНТУ 2016 |