|
БАЗИ ДАНИХ. МОВИ ЗАПИТІВ, УПРАВЛІННЯ ТРАНЗАКЦІЯМИ, РОЗПОДІЛЕНА ОБРОБКА ДАНИХ |
|
3.3 Управління паралельним доступом в розподіленому середовищі
3.3.1 Протоколи блокування для управління паралельним виконанням у розподіленій
базі даних
В розподілених СКБД передбачена можливість одночасного виконання декількома користувачами різних операцій в базі даних. Якщо ці операції здійснюються безконтрольно, то дії користувачів можуть довільним чином впливати один на одного, внаслідок чого база даних може перейти в неузгоджений стан. Якщо виконуються складні запити, пов’язані з пошуком по багатьох файлах бази даних, користувач може почати операції пошуку при одному стані бази даних, а закінчити зовсім при іншому. Це може виникнути в результаті внесення змін у файли бази даних іншими користувачами. Наприклад, при паралельному внесенні змін в один і той самий запис один користувач може стерти зміни іншого користувача. До основних проблем, які мають місце в розподілених СКБД, відносять: - проблема втраченого оновлення, - проблема залежності від проміжних результатів, - проблема неузгодженості обробки, - проблема узгодженості багатьох копій даних. Перші три проблеми характерні і для централізованих СКБД. Остання проблема притаманна саме розподіленим СКБД і виникає в тих випадках, коли існує декілька копій одного елемента даних, розміщених у різних місцях. Очевидно, що для підтримки узгодженості глобальної бази даних при оновленні реплікованого елемента даних на одному з вузлів необхідно відобразити цю зміну і у всіх інших копіях даного елемента. Якщо оновлення не буде відображено у всіх копіях, база даних перейде в неузгоджений стан. Щоб запобігти подібним явищам у розподіленій СКБД здійснюють управління паралельним доступом, яке засноване на підходах з використанням механізмів блокування і тимчасових відміток.
3.3.1 Протоколи блокування для управління паралельним виконанням у розподіленій базі даних
Для управління паралельним доступом використовують такі методи блокування: централізований протокол двофазного блокування, двофазне блокування з первинними копіями, розподілений протокол двофазного блокування та блокування більшості копій. Централізований протокол двофазного блокування. При використанні цього протоколу вся інформація про блокування елементів даних у системі зберігається на єдиному вузлі. Тому у всій розподіленій СКБД існує тільки один планувальник, або диспетчер блокувань, здатний встановлювати і знімати блокування з елементів даних. При запуску глобальної транзакції на вузлі S1 централізований протокол двофазного блокування працює таким чином. 1. Координатор транзакцій на вузлі S1 поділяє глобальну транзакцію на кілька субтранзакцій, використовуючи інформацію, що зберігається в глобальному системному каталозі. Координатор відповідає за дотримання узгодженості бази даних. Якщо транзакція передбачає оновлення реплікованого елемента даних, координатор повинен забезпечити оновлення всіх існуючих копій цього елемента даних. Тому координатор повинен затребувати встановити виключні блокування на всіх копіях оновлюваного елемента даних, а потім звільнити ці блокування. Для читання оновлюваного елемента даних координатор може вибрати будь-яку з існуючих копій. Зазвичай зчитується локальна копія, якщо така існує. 2. Локальні диспетчери транзакцій, які приймають участь у виконанні глобальної транзакції, запитують і знімають блокування елементів даних під управлінням центрального диспетчера блокувань, керуючись при цьому звичайними правилами протоколу двофазного блокування. 3. Центральний диспетчер блокувань перевіряє допустимість вхідних запитів на блокування елементів даних з урахуванням поточного стану блокування цих елементів. Якщо блокування є допустимим, диспетчер блокувань направляє на вихідний вузол повідомлення про те, що необхідне блокування елемента даних надане. У протилежному випадку запит поміщається в чергу, де і знаходиться аж до того моменту, коли необхідне блокування може бути надане. Варіантом цієї схеми є випадок, коли координатор транзакцій виконує всі запити на блокування від імені локальних диспетчерів транзакцій. У цьому випадку диспетчер блокувань взаємодіє тільки з координатором транзакцій, а не з окремими локальними диспетчерами транзакцій. Перевага централізованого протоколу двофазного блокування полягає в тому, що його можна відносно просто реалізувати. Виявлення взаємоблокувань може виконуватися тими ж методами, що і в централізованих СКБД, оскільки вся інформація про блокування елементів знаходиться в розпорядженні єдиного диспетчера блокувань. Основний недолік цієї схеми пов'язаний з тим, що будь-яка централізація в розподіленій СКБД автоматично призводить до появи вузьких місць в системі і різко знижує рівень її надійності та стійкості. Оскільки всі запити на блокування елементів даних спрямовуються на єдиний центральний вузол, його швидкодію обмежують можливості всієї системи. Крім того, відмова цього вузла викликає порушення роботи всієї розподіленої системи, тому вона стає менш надійною. Однак цій схемі притаманний відносно невисокий рівень витрат на передачу даних. Наприклад, глобальна операція оновлення за участю агентів (субтранзакцій) на п вузлах при наявності центрального диспетчера блокувань може зажадати відправки йому не менш 2п+3 повідомлень, у тому числі: один запит на блокування; одне повідомлення про надання блокування; п повідомлень з вимогою оновлення; п підтверджень про виконані оновлення; один запит на зняття блокування. Двофазне блокування з первинними копіями. У цьому варіанті протоколу спроба подолати недоліки централізованого протоколу двофазного блокування виконується за рахунок розподілу функцій диспетчера блокувань по декільком вузлам. У даному випадку кожен локальний диспетчер відповідає за управління блокуванням деякого набору елементів даних. У процесі реплікації для кожного копійованого елемента даних одна з копій обирається в якості первинної копії (primary copy), a всі інші розглядаються як вторинні (slave copy). Вибір первинного вузла може здійснюватися за різними правилами, причому вузол, який обраний для управління блокуванням первинної копії даних, не обов'язково повинен містити саму цю копію. Даний протокол є простим розширенням централізованого протоколу двофазного блокування. Основна відмінність полягає в тому, що при оновленні елемента даних координатор транзакцій повинен визначити, де знаходиться його первинна копія, і послати запит на блокування елемента відповідному диспетчеру блокувань. При оновленні елемента даних досить встановити виняткове блокування тільки його первинної копії. Після того як первинна копія буде оновлена, внесені зміни можуть бути поширені на всі вторинні копії. Це розповсюдження повинно бути виконано з максимально можливою швидкістю, щоб запобігти читання іншими транзакціями застарілих значень даних. Однак немає необхідності виконувати всі оновлення у вигляді однієї елементарної операції. Даний протокол гарантує актуальність значень тільки первинної копії даних. Подібний підхід може використовуватися в тих випадках, коли дані підлягають вибірковій реплікації, їх оновлення відбувається відносно рідко, а вузли не потребують використання найновішої копії всіх елементів даних. Недоліками цього підходу є ускладнення методів виявлення взаємних блокувань у зв'язку з наявністю декількох диспетчерів блокувань, а також збереження в системі певною мірою централізації, оскільки запити на блокування первинної копії елемента можуть бути виконані лише на одному вузлі. Останній недолік може бути частково компенсований за рахунок застосування резервних вузлів, що містять копію інформації про блокування елементів. Даний протокол характеризується меншими витратами на передачу повідомлень і більш високим рівнем продуктивності, ніж централізований протокол двофазного блокування. Це досягається в основному за рахунок менш частого використання віддалених блокувань. Механізм двофазного блокування з первинними копіями запропонований в розподіленій СКБД Ingres. Розподілений протокол двофазного блокування. У цьому протоколі також робиться спроба подолати недоліки, властиві централізованому протоколу двофазного блокування, але вже за рахунок розміщення диспетчерів блокувань на кожному вузлі системи. У даному випадку кожен диспетчер блокувань відповідає за управління блокуванням даних, що знаходяться на його вузлі. Якщо дані не піддаються реплікації, цей протокол функціонує аналогічно протоколу двофазного блокування з первинними копіями. В протилежному випадку розподілений протокол двофазного блокування використовує особливий протокол управління реплікацією, що отримав назву «читання однієї копії та оновлення всіх копій» (Read-One-Write-All – ROWA). У цьому випадку для операцій читання може використовуватися будь-яка копія копійованого елемента, але перш ніж можна буде оновити значення елемента, повинні бути встановлені виняткові блокування на всіх копіях. У такій схемі управління блокуванням здійснюється децентралізованим способом, що дозволяє позбутися недоліків, властивих централізованому управлінню. Однак даному підходу притаманні свої недоліки, пов'язані з суттєвим ускладненням методів виявлення взаємних блокувань (через наявність багатьох диспетчерів блокувань) і зростанням витрат на передачу даних (у порівнянні з протоколом двофазного блокування з первинними копіями), які викликані необхідністю блокувати всі копії кожного оновлюваного елемента. У цьому протоколі виконання глобальної операції оновлення, що має агентів на п вузлах, вимагатиме передачі не менше 5п повідомлень, в тому числі: - п повідомлень із запитами на блокування; - п повідомлень з наданням блокування; - п повідомлень з вимогою оновлення елемента; - п повідомлень з підтвердженням виконаного оновлення; - п повідомлень із запитами на зняття блокування. Ця кількість повідомлень може бути скорочена до 4п, якщо не передавати запити на зняття блокування, яке в цьому випадку буде виконуватися при обробці операцій остаточної фіксації розподіленої транзакції. Розподіленний протокол двофазного блокування реалізований в системі System R*. Блокування більшості копій. Цей протокол можна вважати розширенням розподіленого протоколу двохфазного блокування, в якому усувається необхідність блокування всіх копій реплікованого елемента даних перед його оновленням. У цьому випадку диспетчер блокувань також є на кожному з вузлів системи, де він управляє блокуваннями всіх даних, що розміщуються на цьому вузлі. Коли транзакції потрібно зчитати або записати елемент даних, копії якого є на п вузлах системи, вона повинна відправити запит на блокування цього елемента більш ніж на половину з усіх п вузлів, де є його копії. Транзакція не має права продовжувати своє виконання, поки не встановить блокування на більшості копій елемента даних. Якщо їй не вдасться це зробити за деякий встановлений проміжок часу, вона скасовує свої запити та інформує всі вузли про скасування її виконання. Якщо більшість підтверджень буде отримано, всі вузли інформуються про те, що необхідний рівень блокування досягнутий. Розподілене блокування на більшості копій може бути встановлене одночасно для будь-якої кількості транзакцій, а виключне блокування на більшості копій може бути встановлене тільки для однієї транзакції. У цьому випадку також усуваються недоліки, властиві централізованому підходу. Але даному протоколу властиві власні недоліки, які полягають в підвищеній складності алгоритму, ускладненні процедур виявлення взаємних блокувань, а також необхідності відправки не менше [(n + 1) / 2] повідомлень із запитами на встановлення блокування і [(n + 1) / 2] повідомлень із запитами на скасування блокування.
3.3.2 Усунення взаємних блокувань в розподіленому середовищі
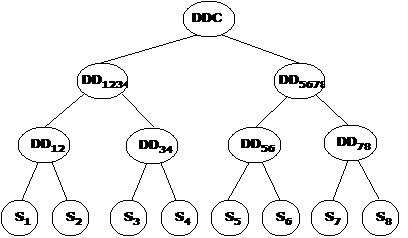
Існують три основні методи виявлення взаємних блокувань в розподіленій СКБД: централізований, ієрархічний і розподілений. Централізований метод виявлення взаємних блокувань. При централізованому виявленні взаємних блокувань один з вузлів системи призначається координатором виявлення взаємних блокувань (Deadlock Detection Coordinator – DDC). Вузол DDC відповідає за побудову та обробку глобального графа очікування. З певним інтервалом кожен диспетчер блокувань в системі направляє на адресу DDC свій локальний граф очікування. Вузол DDC виконує побудову глобального графа очікування і перевіряє його на наявність циклів. Якщо граф очікування містить один або кілька циклів, DDC повинен розірвати кожен цикл, вибравши ті транзакції, які підлягають скасуванню з виконанням відкату, а потім перезапуску. В обов'язки DDC входить інформування всіх вузлів, що приймають участь в обробці транзакцій, які відміняються, про те, що для останніх необхідно виконати відкат і перезапуск. Щоб звести до мінімуму кількість даних, що пересилаються, кожен диспетчер блокування посилає на адресу DDC тільки відомості про зміни в локальному графі очікування, що відбулися з моменту попередньої відправки цих відомостей. Передані відомості включають лише інформацію про додавання або видалення ребер в локальному графі очікування. Недоліком централізованого підходу є те, що він знижує надійність всієї системи, оскільки відмова центрального вузла може викликати великі проблеми у функціонуванні всієї системи. Ієрархічний метод виявлення взаємних блокувань. При ієрархічному методі виявлення взаємних блокувань вузли в мережі створюють деяку ієрархію. На рис. 3.9 зображена ієрархія з восьми вузлів, від S1 до S8. Кожен з вузлів для виявлення наявності взаємних блокувань посилає свій локальний граф очікування на вузол, розташований в ієрархії на рівень вище його.
Рисунок 3.9 – Схема побудови ієрархічного механізму виявлення взаємних блокувань
Перший рівень ієрархії утворюють всі вісім вузлів, кожний з яких виконує локальний контроль наявності взаємних блокувань. Другий рівень утворюють вузли DDij, що забезпечують виявлення взаємних блокувань для сусідньої пари вузлів Si і Sj. Третій рівень утворюють вузли, що виконують контроль взаємних блокувань на чотирьох сусідніх вузлах. Коренем дерева є глобальний детектор взаємних блокувань, здатний виявити взаємні блокування між будь-якими вузлами системи, наприклад між вузлами S1 і S6. Ієрархічний підхід знижує залежність виявлення взаємних блокувань від центрального вузла, а також сприяє зниженню витрат на передачу даних. Проте його реалізація набагато складніша, особливо з урахуванням можливості відмов окремих вузлів і ліній зв'язку. Розподілений метод виявлення взаємних блокувань. Найбільш широко використовується розподілений метод виявлення взаємних блокувань, запропонований Обермарком. У цьому методі для кожного вузла будується локальний графу очікування із додаванням зовнішнього вузла Text, що відображає наявність агента на віддаленому вузлі. Якщо локальний граф очікування містить цикл, що не включає вузол Text, то на вузлі і в розподіленій СКБД існує локальне взаємоблокування. Якщо цикл на локальному графі очікування включає вузол Text, то в системі може існувати глобальне взаємоблокування. Однак існування подібного циклу не обов'язково означає наявність глобального взаємоблокування, оскільки вузол Text може представляти кілька різних агентів. Для уточнення, чи дійсно має місце глобальне взаємоблокування, локальні графи повинні бути об'єднані у глобальний граф очікування. Розподілений метод виявлення взаємоблокувань потенційно більш надійний, ніж ієрархічний та централізований методи, але оскільки жоден з вузлів не містить всієї інформації, необхідної для виявлення взаємоблокування, це може стати причиною високої інтенсивності обміну інформацією між вузлами.
3.3.3 Особливості використання часових відміток для управління паралельним виконанням у розподіленій базі даних
В розподілених базах даних використовуються такі ж протоколи з часовими відмітками, що й в централізованих базах даних. Завданням подібних протоколів є глобальне впорядкування транзакцій таким чином, що більш старі транзакції (ті, що мають меншу часову відмітку) у разі конфлікту отримують пріоритет. У розподіленому середовищі необхідно також виробляти унікальні значення часових відміток, причому як локально, так і глобально. Очевидно, що використання на кожному вузлі системних годинників або накопичувального лічильника подій вже не є прийнятним рішенням. Годинники на кожному вузлі можуть бути недостатньо синхронізовані, а при використанні лічильників подій ніщо не перешкоджає виробленню одних і тих же значень лічильника одночасно на різних вузлах. Загальним підходом у розподілених СКБД є конкатенація локальної часової відмітки з унікальним ідентифікатором вузла у форматі <локальна_відмітка, ідентифікатор_вузла>. Значення ідентифікатора вузла має менший ваговий коефіцієнт, що гарантує впорядкування подій у відповідності з моментом їх виникнення і лише потім у відповідності з місцем їх появи. Щоб запобігти виробленню більш завантаженими вузлами великих значень часових відміток в порівнянні з недовантаженими вузлами, необхідно використовувати певний механізм синхронізації значень часових відміток між вузлами. Кожен вузол поміщає свою поточну часову позначку в повідомлення, що передаються на інші вузли. При отриманні повідомлення вузол-одержувач порівнює поточне значення його часової відмітки з отриманим і, якщо його поточна часова відмітка виявляється меншою, змінює її значення на деяке інше, що перевищує те значення часової відмітки, яке було одержане ним у повідомленні. Наприклад, якщо вузол 1 з поточною часовою відміткою <10, 1> передає повідомлення на вузол 2 з поточною часовою відміткою <15, 2>, то вузол 2 не змінює свою часову відмітку. І навпаки, якщо поточна часова відмітка на вузлі 2 дорівнює <5, 2>, то вузол 2 повинен змінити свою часову відмітку на <11, 2>.
|
|
Пєтух А.М., Романюк О.В., Романюк О.Н. ВНТУ 2016 |