
|
МЕТОДИЧНІ ВКАЗІВКИ
|
|
|
МЕТОДИЧНІ ВКАЗІВКИ
|
Нечіткі логічні системи часто виступають як основна складова систем підтримки прийняття рішень. Задачу прийняття рішень в загальному випадку можна розглядати як задачу ідентифікації, що володіє такими властивостями [16]:
У розробці моделей та методів ідентифікації багатовимірних залежностей на основі нечітких баз знань використовується ряд принципів лінгвістичного моделювання.
Принцип лінгвістичності вхідних та вихідних змінних передбачає, що входи об’єкта та його вихід розглядаються як лінгвістичні змінні, які оцінюються якісними термами. Лінгвістичною називається така змінна, значеннями якої є слова або висловлювання природної мови, тобто якісні терми [8]. Використовуючи поняття функції належності, кожен із термів, що оцінюють лінгвістичну змінну, можна формалізувати у вигляді нечіткої множини, заданої на відповідній універсальній множині.
Прицип формування структури залежності «вхід-вихід» у вигляді нечіткої бази знань. Нечітка база знань являє собою сукупність правил ЯКЩО <входи>, ТОДІ <вихід>, які відображають досвід експерта та його розуміння причинно-наслідкових зв’язків у розглядуваній задачі прийняття рішень. Особливість подібних висловлювань полягає в тому, що їхня адекватність не змінюється при незначних коливаннях умов експерименту. Тому формування нечіткої бази знань можна трактувати як аналог етапу структурної ідентифікації, на якому будується наближена модель об'єкта з параметрами, що вимагають подальшого налаштування. У випадку лінгвістичних систем налаштуванню підлягають форми функцій належності нечітких термів, за допомогою яких оцінюються входи та виходи об'єкта.
Крім того, сукупність правил ЯКЩО-ТО можна розглядати як набір експертних точок в просторі входів та виходів. Застосування апарату нечіткого логічного висновку дозволяє за цими точками відновити багатовимірну поверхню, що дозволяє отримувати значення виходу за різних комбінацій значень вхідних змінних.
Принцип ієрархічності баз знань полягає в рівневому поданні експертних знань. В умовах роботи з багатовимірними даними побудова системи висловлювань, що описують залежність між входами та виходом вистеми, пов’язана з труднощами. З огляду на особливості людської пам’яті не рекомендується будувати логічні висловлювання, що складаються більш як з 9 ознак. Натомість пропонується виконати класифікацію вхідних ознак та на її основі побудувати дерево, що визначає систему вкладених висловлювань меншої розмірності. Можливі також інші шляхи подолання «прокляття розмірності», такі як оптимізація простору вхідних ознак. Крім того, в деяких застосуваннях кваліфікація експерта дозволяє оперувати більшою кількістю вхідних ознак одночасно, але ця кількість також обмежена.
Принцип двохетапного налаштування нечітких баз знань передбачає побудову моделі об’єкта в два етапи, які відповідають етапам структурної та параметричної ідентифікації (рис. 1.4). Налаштуванню підлягають ваги правил та параметри функцій належності. На першому етапі здійснюється формування та початкове налаштування моделі об’єкта шляхом побудови бази знань за доступною експерту інформацією. Для початкового налаштування ваг правил та форм функцій належності застосовується метод парних порівнянь Сааті. Чим вищий професійний рівень експерта, тим вища адекватність нечіткої моделі, побудованої на етапі початкового налаштування.
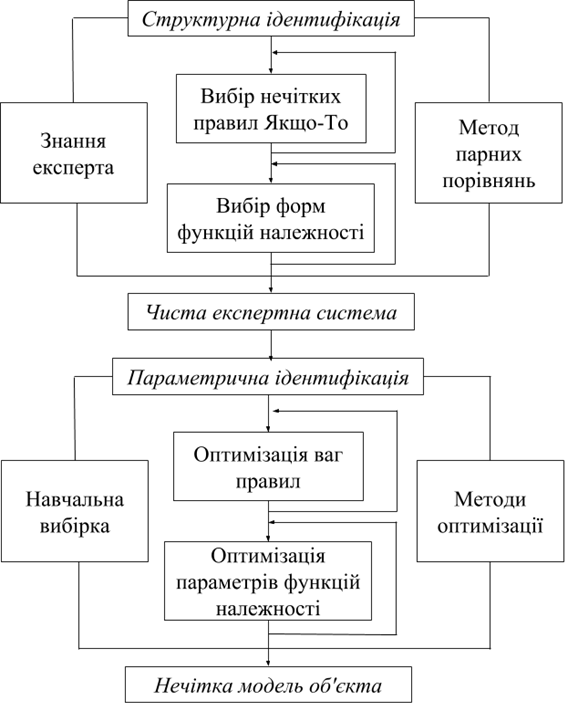
Рисунок 1.4 – Етапи побудови нечіткої логічної системи
Проте результати побудови нечіткого логічного висновку такою системою, побудованою суто на теоретичних знаннях, можуть не узгоджуватись із експериментальними даними. Тому необхідний другий етап, на якому відбувається тонке налаштування нечіткої моделі шляхом її навчання на експериментальних даних. Суть етапу тонкого налаштування полягає в підборі таких ваг нечітких правил ЯКЩО-ТО і таких параметрів функцій належності, які мінімізують розходження між бажаним (експериментальним) і модельним (теоретичним) виходом об'єкта. Етап тонкого налаштування формулюється як задача нелінійної оптимізації, яка може вирішуватися різними методами, серед яких метод найшвидшого спуску та генетичні алгоритми оптимізації.
Основні компоненти нечіткої логічної системи зображено на рис. 1.5.
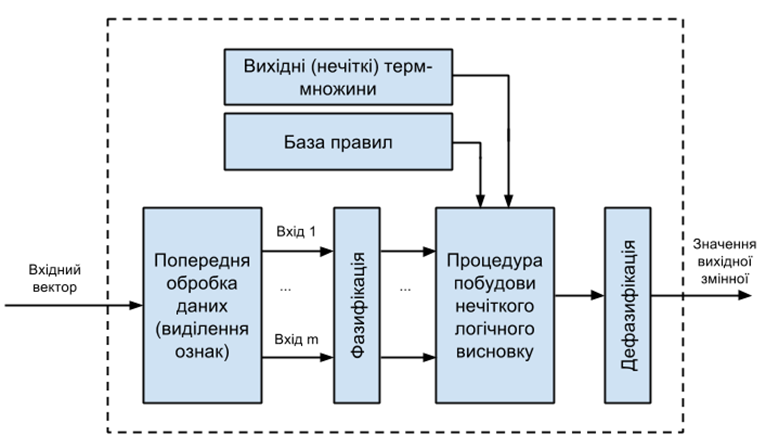
Рисунок 1.5 – Нечітка логічна система класифікації даних
Перед надходженням на вхід нечіткої логічної системи дані можуть піддаватися попередній обробці, наприклад можливе виключення частини ознак із розгляду експертом із предметної галузі.
Практично будь-яка нечітка логічна система має блоки фазифікації, побудови нечіткого логічного висновку, дефазифікації, а також базу знань. Вхідний вектор являє собою набір значень вхідних лінгвістичних змінних ![]() Лінгвістична змінна – це множина нечітких змінних, вона використовується для того, щоб дати словесний опис нечіткому числу, отриманому в результаті деяких операцій.
Лінгвістична змінна – це множина нечітких змінних, вона використовується для того, щоб дати словесний опис нечіткому числу, отриманому в результаті деяких операцій.
Лінгвістична змінна визначається як <x, L, U, G, M>, де x – найменування змінної, L – множина її значень (базова терм-множина), що складається з найменувань нечітких змінних, областю визначення кожної з яких є множина U; G – синтаксична процедура (граматика), що дозволяє оперувати елементами терм-множини L, зокрема генерувати нові осмислені терми; L'=L![]() G(L) задає розширену терм-множину (
G(L) задає розширену терм-множину (![]() – знак об’єднання); M – семантична процедура, що дозволяє приписати кожному новому значенню лінгвістичної змінної нечітку семантику, шляхом формування нової нечіткої множини.
– знак об’єднання); M – семантична процедура, що дозволяє приписати кожному новому значенню лінгвістичної змінної нечітку семантику, шляхом формування нової нечіткої множини.
Терм-множина – це множина всіх можливих значень лінгвістичної змінної.
Терм – будь-який елемент терм-множини. В теорії нечітких множин терм формалізується нечіткою множиною за допомогою функції належності.
Наприклад, змінна «швидкість автомобіля» може набувати значень «низька», «середня», «висока» і «дуже висока». В цьому випадку лінгвістичною змінною є «швидкість автомобіля», термами – лінгвістичні оцінки «низька», «середня», «висока» і «дуже висока», які і складають терм-множину.
Нечіткий терм – це нечітка множина, яка має властивість, якій відповідає певне поняття.
Фазифікація – це процедура перетворення чітких даних у нечітку множину. Процедура фазифікації полягає в формалізації даних як лінгвістичних змінних, введенні всіх можливих термів, що їх характеризують, та побудові функцій належності для кожного терма.
Дефазифікацією (в нечіткій логіці) називається процедура перетворення нечіткої множини в чітке число. В теорії нечітких множин процедура дефазифікації аналогічна знаходженню математичного сподівання, моди або медіани випадкових величин в теорії ймовірностей. Наприклад, таким числом може стати максимум функції належності, центр мас функції належності, або щось інше.
Нечіткою базою знань називається сукупність нечітких правил вигляду “Якщо – ТО”, що визначають взаємозв'язок між входами і виходами досліджуваного об'єкта. Узагальнений формат нечітких правил такий: – “ЯКЩО <антецедент правила>, ТО <консеквент правила>”.
Антецедент правила являє собою твердження вигляду “x є низький”, де “низький” – це терм (лінгвістичне значення), заданий нечіткою множиною на універсальній множині лінгвістичної змінної x. Квантифікатори “дуже”, “більш-менш”, “не”, “майже” і т.п. можуть використовуватися для модифікації термів антецедента.
У випадку, коли база знань будується на основі експериментальних даних, кожна пара (Xі, Yі), де вхідному вектору поставлено у відповідність лінгвістичну оцінку значення вихідної змінної Y, дану експертом, генерує одне правило. Антецеденти правил утворюються заміною значення ![]() відповідним йому нечітким термом
відповідним йому нечітким термом ![]() консеквентами є терм лінгвістичної змінної y, визначений експертом для вектора Xi:
консеквентами є терм лінгвістичної змінної y, визначений експертом для вектора Xi:
![]()
де xі – вхідні змінні, y – вихідна змінна, ![]() – терм-множини вихідної змінної. Терми вхідних та вихідної змінної описуються гаусовими функціями належності вигляду
– терм-множини вихідної змінної. Терми вхідних та вихідної змінної описуються гаусовими функціями належності вигляду

Значення математичного сподівання ![]() при цьому приймаються рівними експериментальним значенням, середньоквадратичне відхилення
при цьому приймаються рівними експериментальним значенням, середньоквадратичне відхилення ![]() вибирається довільним чином.
вибирається довільним чином.
У разі виявлення невідповідності результатів роботи системи, побудованої на емпіричних значеннях параметрів функцій належності, очікуваним значенням можна додатково провести оптимізацію параметрів. Вважається, що результат відповідає очікуваному, якщо терм-множина на виході відповідає висновку експерта.
 Назад
Назад Зміст
Зміст Вперед
Вперед

